|
 Bienvenue dans MyPitSelf Bienvenue dans MyPitSelf
|
 English(US) English(US)
 Français(FR) Français(FR)
|
Cette documentation a été produite avec MyPitSelf00817 |
|
|
|
Bienvenue dans MyPitSelf
|
|
English(US)
Français(FR)
|
Cette documentation a été produite avec MyPitSelf00817 |
 Bienvenue dans MyPitSelf
Bienvenue dans MyPitSelf

|


)
Cliquez et regardez l'image pendant 5 secondes, pas plus. Utilisez le bouton  en haut de la nouvelle fenêtre pour la
fermer.
en haut de la nouvelle fenêtre pour la
fermer.
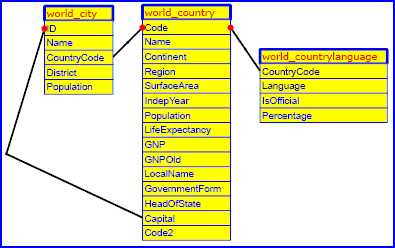
Globalement vous avez vu des boites (les informations) et des flèches qui les relient (les interconnexions entre les informations).
Le problème était que ça devenait trop compliqué car les informations et les interconnexions à gérer étaient si nombreuses que je ne parvenais plus à intégrer toutes les contraintes fonctionnelles
ou techniques liées à ce genre de modèle.
Dans ce cas, on appelle des collègues et on fait de gros projets qui prennent du temps à mettre en place et qui finalement ne satisfont pas toujours les utilisateurs.
 . Le reverse-engineering étant assuré et le premier programme fabriqué avec MyPitSelf étant MyPitSelf lui même, je pense que les fondations ne
sont pas trop mauvaises.
. Le reverse-engineering étant assuré et le premier programme fabriqué avec MyPitSelf étant MyPitSelf lui même, je pense que les fondations ne
sont pas trop mauvaises.
)
)
)
)
) .
.
)
Vous commencez par définir un environnement de travail c'est à dire, vos bases de données (champs, tables, index, liens entre les données ...) et d'autres caractéristiques (constantes , droits des
utilisateurs, menus ...).
Puis vous générez des requêtes SQL simples grâce à un utilitaire permettant de stocker les caractéristiques de ces requêtes dans le système (type de requête, tables et champs utilisés , ...)
Certaines des requêtes sont destinées à afficher les données (SELECT d'une valeur particulière ou SELECT d'une liste de valeurs).
D'autres requêtes sont transformées en fonctions qu'il est possible d'utiliser dans le langage de MyPitSelf (SELECT, INSERT, UPDATE, DELETE).
C'est là que le paradigme d'accès aux données est résolu: comme l'accès aux données est transformé en fonctions, et que ces fonctions sont intégrées aux programmes, il n'y a plus de requêtes SQL
au milieu des programmes source. Seuls les programmes générés contiennent des chaines de caractères contenant les requêtes.
Paradigme: Ensemble des unités qui peuvent commuter dans un contexte donné.
 .
.
.
.
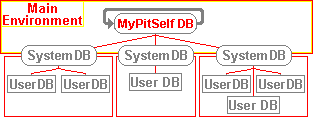
1°) Les SGBD sont des bons systèmes pour stocker et utiliser les données. Ils peuvent aussi être des bons systèmes pour stocker et utiliser les programmes. Donc les programmes devaient être écrits de façon à ce qu'ils puissent être mis en base pour qu'ils puissent être liés aux données qu'ils traitent. C'est pour celà que cet environnement a son propre langage. Ceci veut aussi dire que les programmes sont finalement considérés comme des données, en conséquence, on peut appliquer des traitements aux programmes.
2°) Une fois que les données sont définies, les programmes les traitent. Donc, dans ce système, la première étape est de définir les données et enfin, les programmes peuvent être écrits. Les données de base sont celles définies au niveau dans la base de donnée.
| 3°) Le premier programme écrit avec ce système est lui même car si ce système peut organiser et traiter des données, il permet aussi d'écrire un système pouvant organiser et traiter les données. Ceci explique la boucle dans ce shéma. |
)
|
SELECT T0.Id,T0.Nom,T0.Age FROM $Data.Gens T0 WHERE T0.Age <= %SQLPAR0% ORDER BY T0.Nom ASCUne fonction se nommant R_1203_Select() a alors été produite par le système.
Tac(// Take and call: met des valeurs dans la pile d'appel
// et/ou appel des fonctions.
Cst(30), // constante 30 ans mise dans une pile d'appel
R_1203_Select( // Liste de ces gens, le paramètre SQLPAR0 = 30
Do(
Take(T0.Nom), // mettre le contenu du champ Nom dans la pile d'appel
out(1) // afficher le premier element contenu dans la pile d'appel
) // T0.Nom est retire de la pile d'appel a ce niveau
)
) // 30 est retire de la pile d'appel a ce niveau
Remarque: Les interlignes sont ignorés, on aurait pu tout aussi bien écrire cette fonction sous la forme:
Tac(Cst(30),R_1203_Select(Do(Take(T0.Nom),out(1))))De même, les virgules ne sont pas obligatoires après une ). Une autre forme pourrait être:
Tac( Cst(30) R_1203_Select( Do(Take(T0.Nom),out(1)) ))Les commentaires de bloc sont délimités par /* et */, ils doivent être en colonne 1 et peuvent être imbriqués.
| Ind | Function # | Parent # |
Order In Parent |
Function Name |
Function Type |
Number Of Children |
Level | C1 | C2 |
| 1 | 1 | 0 | 1 | Tac | f | 2 | 1 | ||
| 2 | 2 | 1 | 1 | Cst | f | 1 | 2 | ||
| 3 | 3 | 2 | 1 | 30 | v | 0 | 3 | ||
| 4 | 4 | 1 | 2 | R_1203_Select | f | 1 | 2 | ||
| 5 | 5 | 4 | 1 | Do | f | 2 | 3 | ||
| 6 | 6 | 5 | 1 | Take | f | 1 | 4 | ||
| 7 | 7 | 6 | 1 | T0.Nom | v | 0 | 5 | ||
| 8 | 8 | 5 | 2 | out | f | 1 | 4 | ||
| 9 | 9 | 8 | 1 | 1 | v | 0 | 5 |
//===============================================================
function f_5001(){
global $XVS,$XCS; // variable stack and call stack
$xxSI=sizeof($XCS); // call stack init pos
$xxSC=0; // Stack push count
//===== Start of function =====
//===================
$req4 = "
SELECT T0.Nom FROM `Gens` T0
WHERE T0.Age<=30
ORDER BY T0.Nom ASC " ;
//===================
$result4=mysql_query($req4);
if(mysql_errno()==0){
while($mpsrow4=mysql_fetch_row($result4)){
echo ''.$mpsrow4[0].'
'; // output
}
}else{
return(xxErrSql('1203_SELECT',mysql_error(),$req4,$xxSI));
}
mysql_free_result($result4);
//===== End of function =====
return(true);
}
//===============================================================
L'exemple précédent est simplifié mais vous pourrez voir en cliquant ici quelque chose d'un peu plus trapu: c'est une des fonction assurant la rétro-analyse de
l'exécution d'un programme, elle modifie une forme tabulaire d'une fonction.
<IfModule mod_dir.c> DirectoryIndex index.php </IfModule>
MyPitSelf installation.
Create database Delete database |
MyPitSelf installation.
MyPitSelfxxyzz A été créée avec succès. Vous pouver retourner sur le menu. ou bien Supprimer la base MyPitSelf |
Cliquez là Vers MyPitSelf
Vous obtenez l'écran qui vous demande votre nom d'utilisateur et votre mot de passe
Entrez "1" dans chaque champ et cliquez sur "Entrer". Maintenant si vous obtenez une fenêtre qui ressemble à celle ci, vous pouvez être content!.

|
Sur cet écran, il y a plusieurs boutons dans la barre de menu.
Cliquez dessus si vous voulez mais, pour le moment, ne cliquez pas sur ceux qui ne sont pas sur les menus svp.
Voyons trois d'entre eux:
Le bouton : Qui vous permet d'aller à l'écran initial.
Le bouton  : Qui vous permet d'aller à l'écran précédent.
: Qui vous permet d'aller à l'écran précédent.
Le bouton  : Qui vous permet d'aller voir la doc.
: Qui vous permet d'aller voir la doc.
Le bouton  : Qui vous permet de quitter.
: Qui vous permet de quitter.
Essayez le et réentrez avec 1/1 comme nom d'utilisateur/mot de passe.
Vous verrez dans les exemples permettant de savoit utiliser MyPitSelf des copies d'écrans avec des boutons qui ont une signification standardisée:
 : Nouvel élément
: Nouvel élément
 : dupliquer un élément
: dupliquer un élément
 : voir un élément
: voir un élément
 : Modifier un élément
: Modifier un élément
 : Supprimer un élément
: Supprimer un élément
 : Liste des propriétés d'un élément
: Liste des propriétés d'un élément
 : Déplacer un élément
: Déplacer un élément

)
 .
. ici .
.
.
.
ici .
.
.
.
SELECT T0.ID,T0.Nom,T0.Priorite,T0.xRefUser
FROM
$Data.Taches T0
WHERE T0.Priorite <= %SQLPAR0% and
T0.Nom LIKE '%%SQLPAR1%%' and
T0.xRefUser = %SQLPAR2%
ORDER BY
T0.Priorite DESC ,
T0.ID DESC
LIMIT $xxxlistStart , $xxxlistCount
.
.Tac( Cst(999999999), // paramètre priorité de la tâche Cst(), // paramètre Nom de la tâche ( chaine vide ) VarG(xxUserCode), // Code de l'utilisateur ( variable globale ) Cst(3), // 3 paramètres a0_list( // afficher la liste basée sur ... Sql(1201) // ... la requête 1201 ) )veut dire:
Tac( Cst(999999999), Cst(), VarG(xxUserCode), Cst(3), a0_list( Sql(1201) ) )La fonction a0_list par définition prend 1 ou plusieurs paramètres dans la pile de variables, le premier paramètre ( 3 dans notre cas ) indiquant le nombre de paramètres à prendre dans la pile ( 99999, chaine vide, code utilisateur.
...
.
.
.
.
...
.
.
.
.....
 button gives a result under a table view.
button gives a result under a table view.| Function# |
Parent Number |
Order In Parent |
Function Name |
Function Type |
Number Of Children |
Level |
| 0 | -1 | 0 | 0 | INIT | 1 | 0 |
| 1 | 0 | 1 | f | formula | 2 | 1 |
| 2 | 1 | 1 | g | formula | 1 | 2 |
| 3 | 2 | 1 | x | zone | 0 | 3 |
| 4 | 1 | 2 | h | formula | 1 | 2 |
| 5 | 4 | 1 | y | zone | 0 | 3 |
Tac( T0.ID, doSomething(), )And the new format is:
Tac( Field(T0.ID), doSomething(), )To do this, I wrote functions that did that job.
hello world
SetVar(MyVar01,Cst(Hello),Chr(39),Chr(32),Cst(world)), // puts "hello, world" in MyVar01.
SetVar(MyVar01,Cst(25.5)), // now, it contains 25.5
SetVar(MyVar01,Cst(0)), // now, it contains 0
SetVar(MyVar02,Cst(ACombinedvar),Var(MyVar01)), // MyVar02 contains ACombinedVar0
SetVar(Var(MyVar02),Cst(25.5)) // ACombinedVar0 is created as a new variable
// and contains 25.5
SetVar(toto,Display(1000011)) // puts the content of the message n# 1000011 in toto
button appears on the main menu ( print variable stack ).
AddVar(xxxx,yyyy)Adds to xxxx ( must exist ) yyyy, yyyy can be: Cst(), Var(), n ( a value in the call stack )
SubVar(xxxx,yyyy)Subs to xxxx ( must exist ) yyyy, yyyy can be: Cst(), Var(), n ( a value in the call stack )
MultVar(xxxx,yyyy)Multiply to xxxx ( must exist ) yyyy, yyyy can be: Cst(), Var(), n ( a value in the call stack )
DivVar(xxxx,yyyy)Divide xxxx ( must exist ) by yyyy, yyyy can be: Cst(), Var(), n ( a value in the call stack ) If yyyy = 0, it returns false.
RemainderVar(xxxx,yyyy)xxxx % yyyy . If yyyy = 0, it returns false.
Tac( Test( Cond(IsSet(Var(MyVar))), // or Cond(IsSet(VarG(MyGlobalVar))) IfTrue( // do something ), IfFalse( // do something else ) ) )
Tac(
Var(xxxx), // xxxx is a variable name
VarG(xxxx), // xxxx is a variable name
Cst(yyyy) // yyyy is a constant.
Chr(zzzz) // zzzz is a numeric value for an ascii code
Display(nnnn) // nnnn is a message number.
Field(Tn.FieldName) // The FieldName can be use in LISTFUNCT functions, ie T0.Name
Funct(oooo) // oooo is the number of the function to call
ffff(), // ffff is a function to call whose name is not
// one of the previous in this list
// The Function is called for execution
)
Tac( SetVar(MyVar,Cst(Hello,world)), // defines a variable "myVar" and puts hello, world in it Var(MyVar), // push the variable in the call stack out(1) // outputs the last variable in the call stack ) // all variables pushed in this Tac() are poped
Tac( Field(T0.ID), out(1) )and the result button is in front of the record ID 1234, the source will show something like:
onclick="document.XXFNCT.value='Tac( Cst(1234), out(1) )'"
// Receives the field code and builds the string to build the sql for this field
SetVar(FieldCode,1),
Tac(
Var(FieldCode),
R_1523_Select(
Do(
Take(T0.Name,T0.xRefData),
SetVar(FieldName,2),
SetVar(DataCode,1),
Tac(
Cst(0), // not system
Var(DataCode)
Funct(6091), // builds for example ' varchar(50) NOT NULL
SetVar(SqlString,Cst('`')Var(FieldName),Cst('`'),Ret(1))
// now, SqlString contains `TheFieldName` varchar(50) NOT NULL
)
)
)
Swap(SqlString,1), // the function calling this one can do a
// SetVar(SqlField,Ret(1))
)
Tac( SetVar(DataType,Cst(1002)), SetVar(Value,Cst(1)), FillVar(Libelle,DataType,Value), // Now Libelle contains <img src="cc.gif" /> FillPgmVar(Libelle,DataType,Value), // Now $Libelle contains <img src="cc.gif" /> Ech(Var(Lib)), )
Tac(
SetVar(ExternalRule,DataVal(InternalRuleName,Data(1034))),
SetVar(out,Var(out),sp(),Var(ExternalRule),Cst(':')),
)
Tac(
SetVar(Value,Cst(1234.567))
SetVar(DisplayValue,Num(Value,3)), // Display value contains
// 1 234,567 in french format
// 1,234.567 in us format
)
Tac(
SetVar(sep,Cst(',')),
SetVar(value,Cst('hello,world')),
SetVar(myTab,explode(sep,value)),
SetVar(Co,1),
SetVar(myVal,tab(myTab,Co)), // myVal contains "world"
)
Test( Cond(xxx), [IfTrue(yyy),] [IfFalse(zzz),] )where xxx is the condition: It can be a function ( and usually is ).
SetVar(ValueToTest,1), Tac( Var(ValueToTest), Test( Cond(Equal(0)), // the function Equal return true if the last value in varstack = it's argument. IfFalse( Msg(This will never be displayed but the program continues) ) ) )
SetVar(ValueToTest,Cst(1)), Tac( Var(ValueToTest), Test( Cond(Equal(1)), IfTrue( Msg(I do not want to continue so I exit the program ), ReturnFalse() // this instruction stops the program returning false ) ) )Example 3:
SetVar(ValueToTest,Cst()),
Tac(
Var(ValueToTest),
Test(
Cond(IsVoid()),
IfTrue(
Msg(I DO want to continue ),
),
IfFalse(
Msg(I DO NOT want to continue ),
Test(
Cond(Funct(123456)) // writes in errorlog something
IfTrue(
ReturnFalse() // if we can't write in error log, BIG ERROR
)
)
)
)
)
Test a function result:
Tac(
Var(TableCode),
Var(FieldCode),
Test(
Cond(Funct(Var(T0TestFunct))), // Var(T0TestFunct) contains the function number
IfTrue(
Tac(
// do something
)
)
)
)
LoopVar( xxxx, yyyy, Do(zzzz) )where xxx is a variable containing the number of loops to do.
SetVar(ValueToLoop,3),
LoopVar(
ValueToLoop,ind,
Do(
SetVar(Message,Cst('hello world '),Var(ind)),
Tac(
Var(Message),
out(1) // outputs the 1st value in the call stack
)
)
)
this loop displays hello, world 1 hello, world 2 hello, world 3
SwitchCase( x01,f01(), x02,f02(), ., ., ., [flast()] )x0i are constants, f0i are functions
Tac(
Cst(0),
SwitchCase(
0, out(OK),
1, Tac(
DoManyThings(),
out(OK)
),
out(KO) // default
)
)
outputs OK and continues
Tac(
Cst(2),
SwitchCase(
0, out(OK),
1, out(OK),
out(KO)
)
)
outputs KO, and continuesTac( Cst(2), SwitchCase( 0, out(OK), 1, out(OK) ) )returns false ( it's a bug because the case has not been considered )
Funct(xxxx)where xxxx is the number of the function to call
Equal(xxxx), EEqual(FALSE),EEQUAL(NULL) // does a type check ( === in php ) Greater(xxxx), Lower(xxxx), LowerEqual(xxxx) GreaterEqual(xxxx) IsVoid() IsNotVoid() IsNumeric()where xxxx is a constant or xxxx = Var(yyyy)
Tac(
SetVar(src,Cst('this is a . bug ;')),
// SetVar(src,Cst('$temp="This correct";')),
PhpTest(retour,src),
Var(retour),
Test(
Cond(EEqual(FALSE)),
IfTrue(
out(KO),
ReturnFalse()
),
IfFalse(
out(
OK)
)
)
)
SetVar(FileName,Cst('helloworld.htm')),
SetVar(FileContent,Cst('hello, world')),
a0_File(
FileName(FileName),
FilePtr(fp),
Action(w),
Do(
a0_a0_WriteInFile(FileContent,fp)
)
)
this writes a file "helloworld.htm" containing the string "hello world".
SetVar(FileName,Cst('helloworld.php')),
SetVar(FileContent,Cst(' echo "hello, world\\n" ;')),
a0_File(
FileName(FileName),
FilePtr(fp),
Action(w),
Do(
a0_WriteInSourceFile(FileContent,fp)
)
),
a0_ReadFileInVarStack( xxxx, yyyy )where
a0_File(
FileName(SourceFile), // complete path
FilePtr(sfp),
Action(r),
Do(
SetVar(FileContent,Cst()),
a0_ReadFileInVarStack(FileContent,sfp),
a0_File(
FileName(TargetFile), // complete path
FilePtr(tfp),
Action(w),
Do(
a0_WriteVarStackInFile(FileContent,tfp),
)
)
)
)
SetVar(FilePath,VarG(xxPaWr),VarG(xxDatB),Cst(/../)),
SetVar(FileName,Cst(^.*$)),
Tac(
Var(FilePath),
Var(FileName),
a0_DirList(
SetVar(FileName,3),
SetVar(FileSize,2),
SetVar(FileTime,1),
SetVar(SourceFileContent,Cst()),
SetVar(SourceFile,VarG(xxPaWr),VarG(xxDatB),Cst(/../),Var(FileName)),
SetVar(TargetFile,VarG(xxPtaW),Cst(../),Var(FileName)),
a0_File(
FileName(SourceFile),
FilePtr(SourceFp),
Action(rb),
Do(
a0_ReadFileInVarStack(SourceFileContent,SourceFp),
a0_File(
FileName(TargetFile),
FilePtr(TargetFp),
Action(wb),
Do(
a0_WriteInBinaryFile(SourceFileContent,TargetFp)
)
)
)
)
)
)
a0_Directory(x,path)Where x = c ( create ) or d ( delete ).
Tac( SetVar(TargetBackup,VarG(xxPtaB),LowerCase(SystemDbToBackUp)), a0_Directory(c,TargetBackup), )
a0_DeleteFile(xxxx)Where xxxx = Var(yyyy), yyyy is a variable contaning the name of the file to delete or xxxx = the name of the file
SetVar(FilePath,Cst()), // The path is void ( current path ) SetVar(FileName,Cst(^styles.*\php$)), // file name looks like styles_*.php Tac( Var(FilePath), Var(FileName), SetVar(CurrentSkin,Display(1000063),VarG(xxUserSkin),Cst(
)), Ech(Var(CurrentSkin)), // the current skin is: a0_DirList( SetVar(FileName,3), SetVar(FileSize,2), SetVar(FileTime,1), SetVar(Button,Funct(239)), Tac( Var(FileName), Cst(1), Cst(OPTION), // CLASS of the button Cst(.), // Image Var(FileName), // TITLE (Tool tip of the button) Var(FileName), // text displayed on the button Var(Button), // Function number to call Funct(1001), SetVar(Button1,1,Cst(
)), // Put the html code in a variable to display it ), Ech(Var(Button1)) // displays the button ) )
Tac(
SetVar(DirPath,VarG(xxPaWr)),
SetVar(Patern,Cst('^.*$')),
Var(DirPath),
Var(Patern),
a0_DirDirList(
SetVar(DirName,2),
SetVar(DirTime,1),
Tac(
Var(DirName),
Test(
Cond(Equal(VarG(xxVers))),
IfFalse(
Tac(
SetVar(FromDir,VarG(xxPaWd),Cst('')),
SetVar(ToDir,VarG(xxPaWr),Var(DirName),Cst('/')),
SetVar(FileName,Cst('^a0_styles_[0-9]*\\..*s$')), // .js or .css
Cst(0), // silent does not echo the copy if 1
Var(FromDir),
Var(ToDir),
Var(FileName),
a0_CopyFileDir(),
)
)
)
)
)
)
Tac(
SetVar(DirPath,VarG(xxPaWr)),
SetVar(Patern,Cst('^'),VarG(xxVers),Cst('.*$')),
Var(DirPath),
Var(Patern),
a0_DirDirList(
SetVar(DirName,2),
SetVar(DirTime,1),
Tac(
Var(DirName),
Test(
Cond(Equal(VarG(xxVers))),
IfFalse(
Tac(
SetVar(FromDir,VarG(xxPaWd),Cst('')),
SetVar(ToDir,VarG(xxPaWr),Var(DirName),Cst('/')),
SetVar(FileName,Var(ToDir),Cst('mps_style_*.*')),
a0_DeleteFile(Var(FileName)),
SetVar(silent,Cst(0)), // silent does not echo the copy if 1
SetVar(FileName,Cst('^mps_style_.*s$')), // .js or .css
a0_CopyFileDir(FileName,FromDir,ToDir,silent),
// ..... etc
)
)
)
)
)
)
SetVar(FileName,Cst('file/'),Var(T0name),Cst('.png')),
Var(FileName),
Test(
Cond(FileExist()),
IfTrue(
Tac(
)
),
IfFalse(
Tac(
)
)
),
a0_list( Sql(xxxx), [ShowVar(zzzz),] [FieldToUpdate(iiii),FieldToSee(jjjj),] [Header(Funct(kkkk)),Line(Funct(llll)),] [NoCounter(),] [Hidden(Var(mmmm)),] [Range(Var(nnnn))] )where xxxx is the number of the sql request. It must be a SELECT LIST type.
SELECT T0.Code,T0.Priority,T0.Name,T0.TimeStampCreate,T0.TimeStampUpdate
FROM $xxDatB.yTodo T0
WHERE T0.User = %SQLPAR0% and T0.Priority >= %SQLPAR1% and
ucase( T0.Name ) LIKE ucase( '%yDoc%' ) and T0.Code <= %SQLPAR3%
ORDER BY T0.Priority ASC , T0.Code DESC LIMIT 30
The values %SQLPARn% are the input criterias for the todo list. These values must be put in the call stack before the call to a0_list and you must add the number of parameters of the request as
the last value in the call stack.Tac( Var(xxUserCode), // parameter 1: user code ( %SQLPAR0% ) Cst(0), // parameter 2: priority ( %SQLPAR1% ) Cst(), // parameter 3: content of the todo ( yDoc ) Cst(999999999999999999), // parameter 4: code of the todo ( %SQLPAR3% ) Cst(4), // There are 4 parameters. a0_list( Sql(101) ) )Important point end:
| SELECT DISTINCT | add a "DISTINCT" in front of the select |
| LIST LIMIT | Fixees the number of record to be output |
| Line height | Line height in pixel of the list |
| Cell padding | Cell padding in pixelx of the values in the list |
| OPTION COLUMN WIDTH | width of the column that contains the option buttons |
| Do not put the list in a table | Normally, a list is put in a table, setting this flag to 1 prevents it. |
| GoTo buttons in a list |
Add one more access buttons in a list
|
| Line function | Reference of the line function to use to display the data |
| Header function | |
| NoMenu | |
| Before list function | |
| After list function |
SetVar(ToDisplay,VarG(xxxHeader)), Tac( Var(ToDisplay), Cst(<), CutWithoutLastCharEqual(), // take off </td> SetVar(ToDisplay,1,Cst(<td>Stack</td></tr>)), Ech1(Var(ToDisplay)) )An example of a Line function is
Tac( // Line function of list of 1453 SetVar(Option,VarG(xxxOptionLine)), SetVar(Button,Funct(5574)), VarG(T0Code), Cst(1), Cst(.), // CLASS Cst(u.gif), Display(2000215), Display(2000214), // text displayed on the button Var(Button), Funct(1001), SetVar(Option,Var(Option),1), SetVar(ToDisplay,VarG(xxxStartLine),Var(Option),Cst(</td>),VarG(xxxValueLine),Cst(</tr>)), Ech1(Var(ToDisplay)) ),
 and
and  buttons to see the next records and the counter (xxx->yyyy)/zzz on the top of the list are not displayed
buttons to see the next records and the counter (xxx->yyyy)/zzz on the top of the list are not displayed
a0_Screen( Mode(xxxx), Sql(yyyy), [ShowVar(zzzz),] [After(Funct(iiii))|ScreenAfter(Funct(iiii),] [Replace(T0.jjjj,Var(kkkk)),] [NoLock(),] [NoLog(),] [Under(Funct(llll))] )where
a0_Screen( Mode(Create), Sql(1014), ScreenAfter(Funct(4021)) )
SELECT T0.Code,T0.Priority,T0.Name FROM $xxDatB.yTodo T0 WHERE T0.Code = %SQLPAR0%Note that the T0.Code, the auto incremented field is hidden ( go to the Request menu for select 1002, click on the Fields button, and View the T0.Code Field ).
a0_Screen( Mode(Create), Sql(1002) )
Tac( Field(T0.Code), // first and only parameter of the request a0_Screen( Mode(Update), Sql(1002), NoLock() ) )
a0_AskData( [Display(xxxx),] LaunchButton(Display(ZZZZZZ)), Par(yyyy,zzzz,Default(Var(kkkk)),OnUpdate(Funct(1234)),[,,,] [LaunchButton(llll),|NoLaunchButton()] Tac( SetVar(Value0,Input(0)),[,,,] ffff() ) ) where
xxxx: can be a number and it displays the message number xxxx or Var(VariableName) ant it displays the content of the variable VariableName
llll = Display(iiiii) or Var(eeeee) to display a different text on the launch button than "GO"
yyyy: a string and if equals to Display(nnnn) it displays the message number nnnn
zzzz: either Data(iiii) where iiii is a number of a data in the Data menu
or a function to get the value from a table like
Tac( Cst(i),[,,,] Cst(j), a0_list( Sql(llll), FieldToUpdate(T0.FieldToUpdate), FieldToSee(T0.FieldToSee) ) ) (see the a0_list function for the syntax )
kkkkk is the name of a variable for an initial value
To get the parameters entered, use the syntax:
SetVar(Par0,Input(0)), SetVar(Par1,Input(1)), ....
See below for an example.
This command can also be used to upload a file. In this case, 5 parameters are filled.
Example:
SetVar(idRoot,1),
a0_AskData(
Display(2000409),
Par( Display(2000320), Upload() ),
Tac(
SetVar(FileName,Input(0)),
SetVar(FileType,Input(1)),
SetVar(FileTmp,Input(2)),
SetVar(FileSize,Input(3)),
SetVar(FileErr,Input(4)),
Var(FileErr),
Test(
Cond(Equal(0)), // no error
IfTrue(
Tac(
Var(FileSize),
Test(
Cond(Lower(5000000)),
IfTrue(
// do stuff
),
IfFalse(
out(file greater than 5000000)
)
)
)
)
)
)
)
a big example I use for my own tests is:
SetVar(MonTest,Cst('hello, world')),
SetVar(hidd,Cst(1)),
SetVar(show,Cst(0)),
SetVar(MyDataType,Cst(14)),
a0_AskData(
Display(2000276),
LaunchButton(Display(2000340)),
Par(Display(2000292),Data(Var(MyDataType)),Default(Cst(9999-12-31)),Hide(Var(show))),
Par(Display(2000292),Data(21),Default(Cst(12:00:00)),Hide(Var(hidd))),
Par(
Display(2000292),
Tac(
Cst(),Cst(INTEGER),Cst(0),Cst(9999-12-31),Cst(23:59:59),
VarG(xxDefValDateTime),Cst(9999999),
Cst(7),
a0_list(
Sql(1526),
FieldToUpdate(T0.ID),
FieldToSee(T0.Text)
Data(22)
)
),
Default(Cst(0)),
Hidden(Var(show)),
),
Par(Display(2000292),Data(25),Default(Var(MonTest))), // html type
Par(Display(2000292),Data(27),Default(VarG(xxDefValTimeStamp))),
Par(Display(2000292),Data(9), Default(VarG(xxDefValDateTime))),
Par(Display(2000292),Data(2), Default(Cst(1))),
Par(Display(2000292),Data(26),Default(Cst(1235.02003))),
Par(Display(2000292),Data(20),Default(Cst(1235.02))),
Par(Display(2000292),Data(1002)),
Par(Display(2000292),Data(1015)),
Tac(
out(liste des valeurs egal),
out(11), out(10), out(9), out(8), out(7), out(6), out(5), out(4), out(3), out(2), out(1)
)
)
Tac(
Var(xxxShowForm),
Test(
Cond(Equal(1)),
IfTrue(
Tac(
// if form display
)
)
)
)
Tac( Cst(Hello), Cst(world), out(2), // outputs Hello out(1), // outputs world out(hello world) // outputs hello world ShowMsg(1000011) // outputs Hello SetVar(TheMessage,Display(1000011)), Ech(Var(TheMessage)), // outputs Hello, world )
Tac( Cst(Wait for 2 seconds please), // message displayed out(1), Nap(2) // 2 seconds )
Tac( menu(), LogTheCall(), SetVar(NbTotChap,Cst(0)) R_1798_Select( Do( Take(T0.Code), AddVar(NbTotChap,Cst(1)) ) ), .... )This function is usually used with the LogTheCall() function
Tac( menu(), LogTheCall(), SetVar(NbTotChap,Cst(0)) R_1798_Select( Do( Take(T0.Code), AddVar(NbTotChap,Cst(1)) ) ), .... )This function is usually used withs the menu() function
Tac(
SetVar(MyVar,Cst('<br />hello')),
SetVar(MyHtm,ToHTML(MyVar)), // contains < br > hello
)
R_1585_Select(
Do(
Take(T0.Value),
SetVar(Val,1),
SetVar(JsFileContent,Cst(' Alert(\''),ToJsAlert(Val),Cst('\');\n'))
)
)
R_1585_Select(
Do(
Take(T0.Value),
SetVar(Val,1),
SetVar(JsFileContent,Cst(' var MyJsVariable=\''),ToJsHTML(Val),Cst('\';\n'))
)
)
Tac( SetVar(T0Value,ToHtmlEdit(T0Value)) )
Tac( SetVar(T0Value,ToQuotes(T0Value)) )
Menu(), //Convert to function
a0_AskData(
Par(Display(2000121),Data(6)),
Tac(
SetVar(Original,Input(0)),
SetVar(Original,FunctionEntities(Original)),
SetVar(out,Cst('<pre>Cst(\''),Var(Original),Cst('\')</pre>')),
Ech1(Var(out)),
)
)
So if in input there is ( there is a line feed at the end )
SetVar(NewPassword,2),
SetVar(NewPasswordConfirm,1),
Test( // is the new password = confirmation ( passwords have to be entered twice )
Cond(Equal(Var(NewPassword))),
IfFalse(ShowMsg(1000009),ReturnFalse())
),
Test(
Cond(Match('^([a-zA-Z0-9]{6,32})$')) // contains only alpha
IfFalse(
ShowMsg(1000010),ReturnFalse()
)
)
Tac(
SetVar(DataValueList,Cst('a, b , c , bla bla ')),
CutWithLastChar(DataValueList,Var(DataValueList),Cst(',')),
Ech1(Var(DataValueList)) // outputs "a, b , c ,"
)
Tac(
SetVar(DataValueList,Cst('a, b , c , bla bla ')),
CutWithoutLastChar(DataValueList,Var(DataValueList),Cst(',')),
Ech1(Var(DataValueList)) // outputs "a, b , c "
)
Tac( SetVar(FieldList,Cst(,toto,tata,titi)) SetVar(FieldList,CutString(FieldList,1,1000)), // now contains toto,tata,titi SetVar(FieldList,Cst(toto,tata,titi,)) SetVar(FieldList,CutString(FieldList,0,-1)), // now contains toto,tata,titi )or
SetVar(x,VarG(xxPaWr)),
SetVar(x,Len(x)),
SetVar(Path,VarG(xxPtaI)),
SetVar(Path,Cst('../'),CutString(Path,Var(x),1000)),
Tac( //==================== LowerCase ============ SetVar(str,Cst(HeLLo)), SetVar(str,LowerCase(str)) // contains hello // or SetVar(str,Cst(HeLLo)), Var(str), SetVar(str,LowerCase(1)) // contains hello // or SetVar(str,LowerCase(VarG(xxxVarGvalue))) //==================== UpperCase ============ SetVar(str,Cst(HeLLo)), SetVar(str,UpperCase(str)) // contains HELLO // or SetVar(str,Cst(HeLLo)), Var(str), SetVar(str,UpperCase(1)) // contains HELLO // or SetVar(str,UpperCase(VarG(xxxVarGvalue))) )
Tac( Cst(:), Chr(32), Var(FileName), ReplaceString(), // replace ":" with " " in last value in stack SetVar(FileName,1) )
Tac(
SetVar(Content,Cst('MyFunct(hello)')),
SetVar(Replace,Cst('/MyFunct\\((\\w*)\\)/')),
SetVar(With,Cst('<a href="javascript:popup(\'\\\\1\')"><img src=../sc.gif border="0" alt="" ></a>')),
RepPreg(Replace,With,Content),
)
Tac(
SetVar(ToSearch,Cst('-'),Var(Parent),Cst('-')),
Var(ToSearch),
Var(DocList),
Test(
Cond(StringIsInString()),
IfTrue(
// do the job
)
)
)
SetVar(ToSearch,Cst('/')),
Var(ToSearch),
Var(T0NewValue),
Test(
Cond(StringIsInString()),
IfTrue(
SetVar(pos,strpos(T0NewValue,ToSearch)) // pos contains the position of the string to search.
)
)
Tac(
// ElementName contains '123-456
ToArray(RuleType,ElementName,Cst(-)), // RuleType contains now Array('123','456')
)
SetVar(x,VarG(xxPaWr)),
SetVar(x,Len(x)),
SetVar(Path,VarG(xxPtaI)),
SetVar(Path,Cst('../'),CutString(Path,Var(x),1000)),
Tac(
SetVar(MyVar,Cst('FF')),
SetVar(MyVar,H2D(MyVar)), // Now, MyVar is 255
)
Tac(
SetVar(Level,Cst(5)), // level can be 0
SetVar(out,BranchHeader(Level))
Ech1(Var()), outputs '<tr class=""><td><img width={level}"> '
}
Tac(
SetVar(ToSearch,Cst('-'),Var(DocDisp),Cst('-')),
Var(ToSearch),
Var(DocHiLight),
Test(
Cond(StringIsInString()),
IfTrue(
SetVar(Name,span(ECHO,Name)) // $Name='<span class="zz_echo">'.$Name.'</span>';
)
),
)
or declare a span with an ID
SetVar(Name,SpanId(MYSPAN,ECHO)) // $Name='<span id="MYSPAN" class="zz_echo"></span>';or declare a span with an ID as variable with or without a class
SetVar(Ms,Cst('createFields_'),Var(TableCode)),
SetVar(out,SpanVar(Ms),Var(BAll),SpanEnd()), // $Out='<span id="'.$Ms.'">';
or
SetVar(out,SpanVar(Ms,ZZHID),Var(BAll),SpanEnd()), // $Out='<span id="'.$Ms.'" class="ZZHID">';
or declare a span with an ID and a style
SpanStyle(SvgC,display:inline;), // $Out='<span id="SvgC" style="display:inline;">';or declare a span with a class
SpanClass(ECHO), // $Out='<span class="zz_echo">';or declare a span START with an ID
SetVar(Name,SpanIdSt(MYSPAN,ECHO)) // $Name='<span id="MYSPAN" class="zz_echo">'; // or SetVar(Name,SpanIdSt(MYSPAN)) // $Name='<span id="MYSPAN">';or declare a span End
SetVar(Name,SpanEnd()) // $Name='</span>';
Tac( SetVar(Button,Funct(6202)), Cst(0), Cst(.), Cst(p.gif), Display(2000079), Display(2000079), Var(Button), Funct(1001), SetVar(Button,HiddenSpan(BOT1,1)), Ech1(Var(Button)), CopySpan(BOT1,AFTERFUNCTIONLIST), // or AFTERLISTTITLE for example )
Tac(
SetVar(Button,Cst('<span id="BOT1" style="display:none">'),1,Cst('</span>')),
Ech1(Var(Button)),
CopySpan(BOT1,AFTERLISTTITLE),
)
Or
Tac(
SetVar(Spa01,Cst(BOT1)),
SetVar(Spa02,Cst(AFTERLISTTITLE)),
SetVar(Button,Cst('<span id="BOT1" style="display:none">'),1,Cst('</span>')),
Ech1(Var(Button)),
CopySpan(Var(Spa01),Var(Spa02)), // copy Spa01 in Spa02
)
ClearSpan(MYSPAN), //document.getElementById("MYSPAN").innerHTML="";
Tac(
SetVar(SpNa,Cst('SPLO'),Var(Id)),
HideSpan(SpNa),
// echo '<script>document.getElementById("'.$SpNa.'").style.display="none";</script>';
HideParentSpan(SpNa),
// echo '<script>this.parent.document.getElementById("'.$SpNa.'").style.display="none";</script>';
)
DivStyle(SvgC,display:inline;), // $Out='<div id="SvgC" style="display:inline;">';
SetVar(Name,DivEnd()) // $Name='</div>';
<table border="0" cellpadding="0" cellspacing="0" summary="">
<table border="0" cellpadding="0" cellspacing="0" summary="" align="left">
<td class="nowrap0">
Tac(
SetVar(out,Cst('<table><tr><td class="zz_record">')),
Ech(Var(out)), // the tree is embeded into a table
JsTreeInit(d1,treeCurr,treeInit,Funct(0001),Funct(0002)),
// d1 is the javascript tree object
// funct 0001 is the function to activate a branch
// treeCurr is the reference to the current displayed Id
// treeInit is the reference to the root id of the tree
// funct 0002 is the function to manage the fold/unfold + and - buttons
//========= <branches
Cst(d1), // name of the JsTree object
Var(treeInit),
Var(treeInit),
Var(treeCurr),
Var(treeList),
Cst(0),
Funct(0003) // function to display a branch
//========= branches>
JsTreeOutput(d1,treeList), // outputs the tree
SetVar(out,Cst('</td></tr></table>')),
Ech(Var(out)),
)
Tac( JsTreeInitMove(treeTree,treeCurr,treeInit,Funct(0004),treeToMove), )
Tac( Var(treeDisp), Test( Cond(Equal(Var(treeInit))), IfTrue( JsTreeRoot(TreeRef,treeDisp,Name,HasChild) ), IfFalse( JsTreeElement(TreeRef,treeDisp,Name,HasChild,Parent) ) ) )
JsTreeAdd(TreeRef,treeDisp,BEdit,BAjsBr,BAjApr,BDepla,BSupp), // BEdit,BAjsBr,BAjApr,BDepla,BSupp are the buttons to display
Arg(field), Arg(Value), Tac( JsUpdateParentFieldNumber(field,Value), )Equivalent to
<script type="text/javascript"> this.parent.document.getElementById(\''.$field.'\').value=numberToFormat(\''.$Value.'\'); </script>Updates the "field" in the parent window with a TEXT value
Arg(field), Arg(Value), Tac( JsUpdateParentFieldTEXT(field,Value), )Equivalent to
<script type="text/javascript"> this.parent.document.getElementById(\''.$field. '\').value = \''.str_replace( '\'' , '\\\'' , str_replace( '\\' , '\\\\',$Valeur ) ) . '\'; </script>
R_nnn_Select( Do( Take(T0.FIELDi,T0.FIELDj,,,), // value of the fields are pushed in the call stack ffff() // function[s] is[are] called ) // values of the fields are poped )The field order given in the request can be anything.
Tac( Var(IndiceToDelete), R_nnn_Delete() )The Call stack should contain the parameters of the Delete.
Tac( Var(RecordToUpdate), Var(FieldToUpdate), R_nnn_Update() )The Call stack should contain the parameters of the Update.
Tac(
Var(ValueToInsert),
R_nnnn_Insert(1) // or R_nnnn_Insert(0) if you do not
// want to want to know the last_insert_id
SetVar(NewId,Var(R_nnnn_IOne)), // if R_nnnn_Insert(1)
)
The Call stack should contain the parameters of the Insert.
Tac( Var(ValueToInsert), R_nnn_Manual(ffff()) )The Call stack should contain the parameters of the request.
SetSessionVar(xxx)Updates a session variable with the 2nd last value contained in the call stack.
Tac( Var(NewGroupValue), SetSessionVar(xxUserGroup), Home() )Now, the user will have the menus of the group number contained in the variable NewGroupValue
Tac(
CreateSessionValue(TheNewSessionValue), // define the session value, now,
// xxxSessionTheNewSessionValue exists in the VarStack
Var(TheValue),
SetSessionValue(TheNewSessionValue) // puts TheValue in xxxSessionTheNewSessionValue
)
Then, anywhere in the program, you can use the code:
Tac( Cst(), // put a space in the call stack GetSessionValue(TheNewSessionValue), // puts the session value in the call stack ( replaces the space) SetVar(TheValue,1) // puts the value in a variable. )
Tac( SetVar(UserLogginName,HttpPostVar(XXNAME)), SetVar(UserLogginPassword,HttpPostVar(XXPASS)), )
Tac(
VarG(xxAct),
Test(
Cond(NEqual(GO)),
IfTrue(
Tac(
Cst(0), SetHttpPost(INPUT2),
Cst(0), SetHttpPost(INPUT3)
)
)
)
)
Tac(
SetVar(where,Env('SERVER_SOFTWARE')),
)
The values can be for example:
Tac( Cst(xxxSessionTargetIsOutside), Test( Cond(IsSetSessionVar()), IfTrue( // do something ) ) )
Tac( Cst(INPUT), Test( Cond(IsSetPostVar()), IfTrue( // do something ) ) )
Tac( Cst(s), Test( Cond(IsSetGetVar()), IfTrue( // do something ) ) )
Tac( Cookie(Cst(MyCookieName)), // puts the cookie value of MyCookieName in the stack Test( Cond(Greater(Var(Total))), IfTrue( SetCookie(Cst(MyCookie),Cst(0)) ) ) )Second way: put it in a variable
Tac( SetVar(MyCookieValue,Cookie(Cst(MyCookieName))), Var(MyCookieValue), Test( Cond(Greater(Var(Total))), IfTrue( SetCookie(Cst(MyCookie),Cst(0)) ) ) )
Tac( // these functions use javascript to display the date SetVar(MyDate,Cst(2003-10-05)), SetVar(MyDate,DateUser(MyDate,0)), // Contains 05/10/03 if we are in france ( DMY format ) SetVar(MyDate,DateUser(MyDate,1)), // Contains Lu 05/10/03 if we are in france ( DMY format ) SetVar(MyDate,DateUser(MyDate,2)), // Contains Lundi 05/10/03 if we are in france ( DMY format ) SetVar(MyDate,DateUser(MyDate,3)), // Contains Lundi 05 Octobre 2003 // If you want to use php to convert the date, use DateServer instead of DateUser )
Tac( Cst(2003-12-31), a0_AddOneDay(), out(1) // outputs 2004-01-01 )
Tac( Cst(2003-12-31), FormatDate(), out(1), UnformatDate(), out(1), a0_AddOneDay(), out(1), a0_DayOfWeek(), out(1), // outputs 4 )
Tac(
a0_useRev_0(),
SetVar(TheSource,
Cst('Tac(Cst(30),R_1203_Select(Do(Take(T0.Nom),out(1))))')
),
Rev_SourceToArray(FunctionSource,tf),
)
Now, tf is an array containing :
| Ind |
Function Number |
Parent Number |
Order in Parent |
Function Name |
Function Type |
Number of Children |
Level | C1 | C2 |
| 0 | 0 | -1 | 0 | 0 | INIT | 1 | 0 | ||
| 1 | 1 | 0 | 1 | Tac | formula | 2 | 1 | ||
| 2 | 2 | 1 | 1 | Cst | formula | 1 | 2 | ||
| 3 | 3 | 2 | 1 | 30 | Value | 0 | 3 | ||
| 4 | 4 | 1 | 2 | R_1203_Select | formula | 1 | 2 | ||
| 5 | 5 | 4 | 1 | Do | formula | 2 | 3 | ||
| 6 | 6 | 5 | 1 | Take | formula | 1 | 4 | ||
| 7 | 7 | 6 | 1 | T0.Nom | zone | 0 | 5 | ||
| 8 | 8 | 5 | 2 | out | formula | 1 | 4 | ||
| 9 | 9 | 8 | 1 | 1 | Value | 0 | 5 |
Tac(
a0_useRev_0(),
Rev_ArrayToSource(tf,FunctionSource),
// now, Function source contains
// Cst('Tac(Cst(30),R_1203_Select(Do(Take(T0.Nom),out(1))))
)
Tac( a0_useRev_0(), Rev_SourceToArray(FunctionSource,tf), Rev_ArrayToTable(tf), // Load an array in the table yArrayFunct // Do big work on table yArrayFunct Rev_TableToArray(tf), Rev_ArrayToSource(tf,newSource), )
Tac( a0_useRev_0(), Rev_SourceToArray(FunctionSource,tf), Rev_ArrayToTable(tf), // Do big work on table yArrayFunct Rev_TableToArray(tf), // Load the content of table yArrayFunct to an array Rev_ArrayToSource(tf,newSource), )
Tac( Cst(a0_AskData), Cst(a0_list), Cst(a0_Screen), Cst(3), // function count to take off Rev_TakeOffFunct(FormuleFinale), )
Tac( SetVar(Button,Funct(xxxx)), // put the function to call (xxxx) with this button in a variable Var(Value01), // argument 1 for the function xxxx Var(Value02), // argument 2 for the function xxxx Var(Value03), // argument 3 for the function xxxx Cst(3), // argument count Cst(.), // CLASS ( . = normal link ) Cst(.), // Image . if none or the name of the image in the /img directory Display(2000018), // TITLE (Tool tip of the button) Display(2000019), // text if no images Var(Button), // Function number to call Funct(1001), // or 1002 for confirm SetVar(Button,1), // Put the html code in a variable to display it Ech(Var(Button)) // displays the button )The result is a button that executes the function
Tac( Cst(1), // content of Var(Value01) Cst(2), // content of Var(Value02) Cst(3), // content of Var(Value03) Funct(xxxx) )1, 2 and 3 were contained in Valus01, Valus02, Valus03.
Tac( SetVar(BMajTitre,Funct(6783)), // function to call Var(DocDict), // argument one Cst(1), // 1 argument Cst(OPTION), // CLASS of the button Cst(u.gif), // Image Display(2000308), // TITLE (Tool tip of the button) Display(2000308), // text displayed if no image Cst(0), // x top Cst(0), // y left Cst(0), // x width Cst(0), // y height Var(BMajTitre), // funct number to call Funct(1003), SetVar(BMajTitre,1), // BMajTitre contains the code ),The result is a button that opens an other window and executes the function
Tac( Cst(123456), // content of Var(DocDict) Funct(6783) )
Tac(
SetVar(ToCall,Cst('Funct('),Funct(5001),Cst(')')),
Var(ToCall),
Funct(1009)
)
Tac(
SetVar(SpanValue,Cst('hello')),
SetVar(Sid,Cst('MySpanId')),
Var(SpanValue),
Var(Sid),
Funct(1015) // updates the content of a span
)
SetVar(Formula,
Cst('Tac(Cst('),
Var(TableCode),
Cst('),ac_yTable_CreateSelectRequest())')
),
Tac(
Var(Formula),
CallFormulaInStack() // The function is submited
)
SetVar(Hidden,
Cst('SetVar(IdContact,Cst('),Var(IdContact),Cst(')),'),
Cst('SetVar(Critere,Cst(\'\'))'),
),
And in the line function, I use
Tac( VarG(xxHidd), ExecuteFormulaInStack(), SetVar(IdContact,VarG(IdContact)) )
Tac( VarG(T0Source), // See if the function is good first Test( Cond(TestFormula()), IfFalse(ReturnFalse()) ) )
Tac( a0_Batch(Funct(xxxx)[,Log(0|1)]), // or a0_Batch(a0_yyyy([a0_zzzz])[,Log(0|1)]) )where xxxx is the function number to execute
OutputBuffering( // start buffering
Tac( // do the job
Var(RFileContent),
PhpEvalNoReturn(), // I want to save the result of this action
OutputBufferingGetContents(), // I call this, the VarStack now contains the output
SetVar(WFileContent,1) // and I save it in a variable
a0_File(
FileName(CSSFile),
FilePtr(fpw),
Action(w),
Do(
a0_WriteVarStackInFile(WFileContent,fpw)
)
)
)
)
Tac( Var(FileContent), PhpTest(), Test( Cond(EEqual(FALSE)), // test this php function IfTrue( ShowMsg(2000252), ReturnFalse() ) ) )
// replace in ySource html by tidy html
a0_useHtml_0()
Cst(0),
R_1892_Select(
Do(
Take(T0.Code,T0.Type,T0.Name,T0.Source),
SetVar(T0Code,4),
SetVar(T0Type,3),
SetVar(T0Name,2),
SetVar(T0Source,1),
Tac(
Var(T0Code),
Var(T0Type),
Test(
Cond(Equal(DOC)),
IfTrue(
Tac(
SetVar(IsHt,Cst(0))
SetVar(ToSearch,Cst('.htm')), Var(ToSearch), Var(T0Name),
Test(Cond(StringIsInString()),IfTrue(SetVar(IsHt,Cst(1))))
SetVar(ToSearch,Cst('.html')), Var(ToSearch), Var(T0Name),
Test(Cond(StringIsInString()),IfTrue(SetVar(IsHt,Cst(1))))
Var(IsHt),
Test(
Cond(Equal(2)), // change this to 1 to do the job
IfTrue(
Tac(
SetVar(T0Source,html_ToXhtml(T0Source)),
SetVar(T0Source,html_getBodyContent(T0Source)),
Var(T0Code),
Var(T0Source),
R_1698_Update()
)
),
),
Var(T0Code),
Test(
Cond(Equal(12)), // do it for one source
IfTrue(
Tac(
Var(T0Code),
Var(T0Source),
// R_1698_Update()
Ech1(Var(T0Source)),out()
)
),
),
)
),
),
)
)
), // 1892
|
A screen copy of this tool can be seen here. |
)
|
 Maquillage button
Maquillage button
 .
.
.
.
.
.
.
.
.
.
update yUser SET Name='1', PassWord='6512bd43d9caa6e02c990b0a82652dca' WHERE Code=1

Option Compare Database
Option Explicit
'====================================================================================
' This VB procedure extract from an Access database to a mysql format :
' the table structure and puts it in a file named c:\temp\stru.sql,
' the table values and puts it in a file named c:\temp\data.sql,
'================================== It can be easily modified to match your criterias
'====================================================================================
'====================================================================================
'===================== UPDATE THIS FOR your local window setting ====================
Const Mydecimalseparator = "," ' france,italy,spain:"," , US,GB:"." ,
'====================================================================================
'Create a directory name c:\temp\
'Insert this in a vb module, place your cursor inside the extract function, and press
' the F5 key (run) on your keyboard
' If a case is not provided, the output contains an XX string so you can find
' problems looking for the "XX" string
'====================================================================================
Type typfld
nam As String
typ As Integer
End Type
'====================================================================================
Sub Extract()
Dim tdf As DAO.TableDef
Dim fld As DAO.Field
Dim i As Integer
Dim j As Integer
Dim typ As String
Dim dba As Database
Dim rst0 As Recordset
Dim shea As String
Dim sdat As String
Dim ttypfld(0 To 499) As typfld
Dim val As Variant
Dim fou As Boolean
Dim dattim As Date
Dim auto As String
Dim dbl As Double
Open "c:\temp\stru.sql" For Output Access Write As #1
Open "c:\temp\data.sql" For Output Access Write As #2
For Each tdf In CurrentDb.TableDefs
If Mid(tdf.Name, 1, 4) = "MSys" Then ' do not take MSACCESS system tables
Else
Print #1, "CREATE TABLE `" & MyNam(tdf.Name) & "` ("
i = 0
auto = ""
For Each fld In tdf.Fields
ttypfld(i).nam = fld.Name
ttypfld(i).typ = fld.Type
typ = ""
If fld.Type = 1 Then typ = "ENUM('0','1')"
If fld.Type = 3 Then typ = "INTEGER"
If fld.Type = 4 Then typ = "BIGINT"
If fld.Type = 5 Then typ = "DECIMAL(17,2)"
If fld.Type = 6 Then typ = "FLOAT"
If fld.Type = 7 Then typ = "DOUBLE"
If fld.Type = 8 Then typ = "datetime"
If fld.Type = 10 Then typ = "varchar(" & fld.Size & ")"
If fld.Type = 11 Then typ = "BLOB"
If fld.Type = 12 Then typ = "TEXT"
If typ = "" Then typ = "XX " & fld.Type & " XX"
If fld.Required Then
typ = typ & " NOT NULL"
End If
If fld.Attributes = 17 Then
typ = typ & " AUTO_INCREMENT NOT NULL"
auto = MyNam(fld.Name)
ElseIf fld.Attributes = 1 Or fld.Attributes = 2 Then
typ = typ ' I don't know
ElseIf fld.Attributes = 32770 Then
typ = typ & "" ' hypertext link
Else
typ = typ & " XXX" & fld.Attributes & "XXX "
End If
If fld.AllowZeroLength Then
typ = typ & " fld.AllowZeroLength"
End If
Print #1, " `" & MyNam(fld.Name) & "` " & typ & ","
i = i + 1
Next
If auto <> "" Then Print #1, " PRIMARY KEY (`" & auto & "`),"
Print #1, ");"
Print #1, ""
shea = "INSERT INTO " & MyNam(tdf.Name) & " VALUES("
Set dba = CurrentDb()
Set rst0 = dba.OpenRecordset(" SELECT * FROM [" & tdf.Name & "] ", dbOpenDynaset)
Do Until rst0.EOF
sdat = ""
For j = 0 To i - 1
val = rst0(ttypfld(j).nam)
fou = False
If ttypfld(j).typ = 1 Then
sdat = sdat & "'"
If val Then
sdat = sdat & "1',"
Else
sdat = sdat & "0',"
End If
fou = True
End If
If ttypfld(j).typ = 3 Or ttypfld(j).typ = 4 Or ttypfld(j).typ = 5 Or ttypfld(j).typ = 6 Or ttypfld(j).typ = 7 Then
If IsNull(val) Then
sdat = sdat & "NULL,"
Else
dbl = val
sdat = sdat & Replace(CStr(dbl), Mydecimalseparator, ".") & ","
End If
fou = True
End If
If ttypfld(j).typ = 10 Or ttypfld(j).typ = 12 Then
If IsNull(val) Then
sdat = sdat & "NULL,"
Else
sdat = sdat & "'" & Replace(Replace(Replace(val, "\", "\\"), "'", "\'"), vbCrLf, "\r\n") & "',"
End If
fou = True
End If
If ttypfld(j).typ = 8 Then
If IsNull(val) Then
sdat = sdat & "NULL,"
Else
dattim = val
sdat = sdat & "'" & Format(dattim, "yyyy") & "-" & Format(dattim, "mm") & "-" & Format(dattim, "dd") & " " & Format(dattim, "hh:mm:ss") & "',"
End If
fou = True
End If
If ttypfld(j).typ = 11 Then
If IsNull(val) Then
sdat = sdat & "NULL,"
Else
sdat = sdat & "'',"
End If
fou = True
End If
If fou Then
Else
sdat = sdat & " XXX " & val & " XXX "
End If
Next
sdat = Mid(sdat, 1, Len(sdat) - 1) & ");"
If fou Then
Print #2, shea & sdat
Else
Print #2, "#" & shea & sdat
End If
rst0.MoveNext
Loop
End If
Print #2, ""
Next
Close #1
Close #2
End Sub
'====================================================================================
Function MyNam(nam) As String ' Converts a fancy table name like "Détails commandes"
' to "details_commandes"
Dim i As Integer
MyNam = ""
Dim c As String
For i = 1 To Len(nam)
c = Mid(nam, i, 1)
If (Asc(c) >= Asc("a") And Asc(c) <= Asc("z")) Or (Asc(c) >= Asc("A") And Asc(c) <= Asc("Z")) Or (Asc(c) >= Asc("0") And Asc(c) <= Asc("9")) Then
MyNam = MyNam & LCase(c)
ElseIf c = "é" Or c = "è" Then ' ( this is for france, update it for other languages )
MyNam = MyNam & "e"
ElseIf c = "à" Then
MyNam = MyNam & "a"
Else
MyNam = MyNam & "_"
End If
Next
End Function
'====================================================================================
DROP TABLE IF EXISTS `Group`; CREATE TABLE `Group` ( `IdGroup` BIGINT( 20 ) UNSIGNED NOT NULL AUTO_INCREMENT , UNIQUE (`IdGroup` ) ); INSERT INTO `Group` VALUES (1),(2),(3),(4),(5); DROP TABLE IF EXISTS `Auth`; CREATE TABLE `Auth` ( `groupId` BIGINT(20) UNSIGNED NOT NULL default '0', `menuId` BIGINT(20) UNSIGNED NOT NULL default '0' ); INSERT INTO `Auth` VALUES (0, 1); INSERT INTO `Auth` VALUES (2, 1) , (2, 2) , (2, 3) , (2, 4) , (2, 5) ; INSERT INTO `Auth` VALUES (3, 1) , (3, 2) , (3, 3) , (3, 4) , (3, 9) ; # tous les groupes et leurs autorisations ( NULL si aucune autorisation pour un utilisateur ) SELECT T1.IdGroup, T0.menuId FROM `Auth` T0 RIGHT OUTER JOIN `Group` T1 ON ( T0.groupId = T1.IdGroup ) ; #returns: 1,NULL| 2,1 | 2,2 | 2,3 | 2,4 | 2,5 | 3,1 | 3,2 | 3,3 | 3,4 | 3,9 | 4,NULL | 5,NULL # tous les groupes qui n'ont pas d'autorisations ( sql précédent plus recherche de NULL ) SELECT T1.IdGroup, T0.menuId FROM `Auth` T0 RIGHT OUTER JOIN `Group` T1 ON ( T0.groupId = T1.IdGroup ) WHERE T0.menuId IS NULL ; #returns: 1,NULL | 4,NULL | 5,NULL # tous les groupes avec autorisations SELECT T1.IdGroup, T0.menuId FROM `Auth` T0 INNER JOIN `Group` T1 ON (T0.groupId=T1.IdGroup); #returns: 2,1 | 2,2 | 2,3 | 2,4 | 2,5 | 3,1 | 3,2 | 3,3 | 3,4 | 3,9 # Groupes dans la table des autorisations qui ne sont pas référencés dans la table des groupes SELECT T0.groupId , T0.menuId FROM Auth T0 LEFT JOIN `Group` T1 ON T0.groupId=T1.IdGroup WHERE T1.IdGroup IS NULL; #returns: 0,1
FCKConfig.ToolbarSets["mypsFckHtml1"] = [
['Source','NewPage','Cut','Copy','Paste','PasteText','PasteWord'],
['Undo','Redo','Find','Replace','SelectAll','RemoveFormat','JustifyLeft','JustifyCenter','JustifyRight','JustifyFull'],
['OrderedList','UnorderedList'],
'/',
['Bold','Italic','Underline','StrikeThrough','Subscript','Superscript','FontSize','TextColor','BGColor'],
['Outdent','Indent','Blockquote'],
['Table','Rule','SpecialChar','PageBreak','ShowBlocks','About']
] ;
$string = <<<XML
<a>
<b>
<c>text <b>hello</b><i>hello</i></c>
<c>stuff</c>
</b>
<d>
<c>hella</c>
</d>
</a>
XML;
function subTree( $s , $tag ){
if(substr($s,0,1+strlen($tag))!='<'.$tag) return false;
$news='';
for($i=1+strlen($tag);$i<strlen($s);$i++){
if(substr($s,$i,1) == '>') break;
}
$news=substr($s,$i+1);
if( substr($news,strlen($news)-strlen($tag)-3) !='</'.$tag.'>') return false;
return(substr($news,0,strlen($news)-strlen($tag)-3));
}
$xml = new SimpleXMLElement($string);
echo '<textarea rows="10" cols="40">' . $xml->asXML() . '</textarea><br />';
echo '<textarea rows="6" cols="40">' . $xml->b->asXML() . '</textarea><br />' ;
echo '<textarea rows="6" cols="40">' . subTree( $xml->b->asXML() , 'b' ) . '</textarea><br />' ;
?>